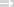Alle bisherigen Überlegungen beziehen sich auf ein Dokument. Indexierte Dokumente sind in der Regel jedoch Teil einer Dokumentensammlung (z.B. digitale Pressearchive). Für eine Dokumentsammlung lässt sich die Bedeutung der Worthäufigkeit präzisieren. Ein Stichwort ist umso aussagekräftiger für den Inhalt eines Dokumentes, desto häufiger es in einem Dokument auftritt, und je seltener es in der Datenbank insgesamt vorkommt. Wie man die Häufigkeit eines Wortes in der Dokumentenkollektion mit in die Berechnung einbezieht, regelt die inverse Dokumentenhäufigkeit = inverse document frequency (IDF).
Die inverse Dokumentenhäufigkeit (IDF) gibt die Relation der Dokumente, in denen das Wort vorkommt, zur Anzahl aller Dokumente in der Datenbank an. Um die Spannweite der errechneten Werte nicht allzu groß werden zu lassen, arbeitet man auch hier mit logarithmischen Werten. Die klassische Berechnungsformel nach Sparck-Jones lautet:
IDF(i) = (log2 N /n) + 1 |
Abkürzungen:
IDF(i) = inverse document frequency des Wortes i
N = Gesamtzahl der Dokumente in der Datenbank. Dieser Wert ändert sich ständig bei schnell wachsenden Datenbanken wie Internet Suchmaschinen
n = Anzahl der Dokumente, in denen i vorkommt
Beispiel:
Ausgangspunkt sei eine Kochbuchdatenbank mit den Volltexten von ungefähr 1.000 Rezepten. Zitrone kommt in 300 Rezepten vor.
Es gibt 2 Rezepte mit Pekanüssen
Salz kommt in 800 Dokumenten der Sammlung vor.
|
Das Verfahren zur statistischen Ermittlung von geeigneten Deskriptoren für Texte beruht also auf folgenden Annahmen:
Man verbindet nun die Errechnung der Termfrequenz mit der Errechnung der inversen Dokumenthäufigkeit. Damit ist das Gewicht, also die angenommene Qualität des Deskriptors, abschließend berechnet. Die gängige Formel für die Errechnung der Termgewichte lautet:
TF x IDF |
Stand: 1. März 2005