Clustering: Klassifikation ohne vorgegebenes Klassifikationssystem
Das Clustering von Dokumenten basiert auf der Ermittlung von Ähnlichkeit bzw. Differenz von Dokumenten nach vorgegebenen Merkmalen. Eine einfache Form der Bestimmung von Merkmalen ist das Vorkommen gemeinsamer Deskriptoren. In der Praxis berücksichtigen die Systeme viele zusätzliche Eigenschaften wie Wortlänge, Distanz von Wörtern usw. Der Einfachheit halber gehen wir für die weiteren Überlegungen von statistisch oder intellektuell ermittelten Deskriptoren aus. Zunächst werden alle Dokumente einer begrenzten Ausgangsdatenmenge paarweise miteinander multipliziert. Auf diese Weise erhält man eine Dokument-Dokument-Ähnlichkeitsmatrix. Im Anschluss wird ein Schwellenwert festgelegt; alle Dokumentpaare, die diesen Wert überschreiten werden gruppiert.
| Dok 1 | Dok 2 | Dok 3 | Dok 4 | Dok x | |
| Dok 1 | - | 2,2 | 1,2 | 2,0 | ??? |
| Dok 2 | 2,2 | - | 1,8 | 3,6 | ??? |
| Dok 3 | 1,2 | 1,8 | - | 1,3 | ??? |
| Dok 4 | 2,0 | 3,6 | 1,3 | - | ??? |
| Dok x | ??? | ??? | ??? | ??? | - |
Wenn wir nur die vier eingetragenen Dokumente vergleichen, erhalten wir bei einem Schwellenwert von 2,0 ein Cluster, das aus den Dokumenten 1,2 und 4 besteht. In der Praxis würde man natürlich mit wesentlich mehr Dokumenten arbeiten und hätte nach diesem ersten Arbeitsschritt eine ganze Reihe von Clustern.
Diese Cluster würden folgendermaßen weiterverarbeitet. Für die Dokumente eines Clusters wird ein sogenannter Zentroidvektor ermittelt. Der Zentroidvektor ergibt sich aus dem Mittelwert aller Dokumentvektoren des Clusters. In der Tabelle sehen Sie, wie der Zentroidvektor für drei Dokumente, die durch die Vektoren "Bundeskanzler, Birne, Helmut Kohl und Euro", dargestellt werden, aussieht.
| Bundeskanzler | Birne | Helmut Kohl | Euro | |
| Vektor Dok 1 | 1 | 1 | 0 | 1 |
| Vektor Dok 2 | 1 | 1 | 1 | 1 |
| Vektor Dok 3 | 1 | 1 | 0 | 1 |
| Vektor Dok 4 | 1 | 0 | 1 | 1 |
| Zentroidvektor | 4/4 = 1,0 | 3/4 = 0,75 | 2/4 = 0,5 | 4/4 = 1,0 |
Clustering ist ein mehrstufiger Prozess
- Zunächst wird eine Ausgangskonfiguration aus einigen wenigen Clustern erstellt, für die jeweils ein Clusterrepräsentant, also ein Zentroidvektor, ermittelt wird.
- Neu hinzukommende Dokumente werden mit allen Clusterzentroiden verglichen.
- Das Cluster mit der maximalen Ähnlichkeit wird ermittelt und das Dokument wird in das Cluster integriert. Wenn Überlappungen zwischen den Clustern erlaubt sind, wird das Dokument in alle Cluster integriert, für die der Ähnlichkeitswert einen bestimmten Schwellenwert überschreitet.
- Nach der Dokumentzuweisung müssen die Clusterzentroiden neu berechnet werden. In einem nächsten Bearbeitungsschritt werden die Schritte 2 bis 4 erneut durchlaufen.
- Das Verfahren wird nach einer vorher festgelegten Anzahl der Wiederholungen der Schritte 2 bis 4 beendet.
Auf diese Weise erhalten Sie eine Reihe disjunkter oder sich überschneidender Cluster, die allerdings noch keine Benennung haben. Verschiedene Verfahren der Benennung sind denkbar. Im einfachsten Fall werden der oder die am stärksten gewichteten Deskriptoren des Zentroidvektors als Benennung des Clusters ausgegeben.
Quelle: Salton, Gerard; McGill, Michael: Information Retrieval - Grundlegendes für Informationswissenschaftler. - Hamburg u. a.: Mc Graw-Hill Book Company Gmbh, 1987, S. 228-236.
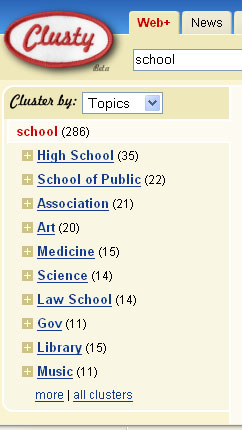
In der Abbildung sehen Sie zwei Beispiele für Cluster zum Thema School aus der Suchmaschine www.clusty.com. Je nachdem, ob Sie in dem Bestand Web oder News suchen, unterscheiden sich die Cluster und ihre Benennungen.
 |
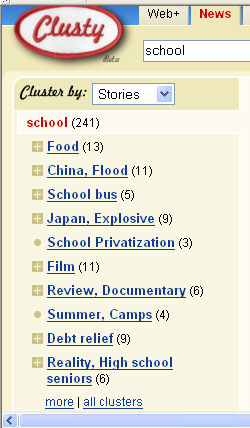 |
Abb.: Ausschnitt Clusterergebnisse www.clusty.com zur Suche nach school. - Stand: 13.06.05
Stand: 05. Juli 2005