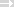Das Vektorraummodell wird auch verwendet, um den Grad der Ähnlichkeit zwischen einer Suchformulierung und Dokumenten in der Datenbank zu berechnen. Dabei kann man auch die Gewichte ausgewählter Wörter im Text, die man mit der Formel tf*idf errechnet hat, (anstelle 1=kommt vor, 0=kommt nicht vor) in der Ähnlichkeitsberechnung berücksichtigen. Unsere Tabelle könnte dann folgendermaßen aussehen:
| Wort im Text (tf * idf) | Dok 1 | Dok 2 | Dok 3 | Dok 4 |
| Studenten | 0 | 1,5 | 0 | 1,5 |
| Protest | 0,5 | 0,25 | 0,75 | 1,0 |
| Sparmaßnahmen | 1,0 | 2,0 | 0,75 | 0,5 |
| Sternmarsch | 0,25 | 0,25 | 0,4 | 0,5 |
| Senat | 2,0 | 0 | 1,5 | 2,8 |
Ein Datenbanknutzer gibt folgende Suchformulierung ein:
Welche Dokumente sind dieser Suchanfrage am ähnlichsten? Für den Fragevektor gehen Sie für alle in der Suchanfrage vorhandenen Suchbegriffe von einem Gewicht von 1 aus und für die nicht vorhandenen Suchbegriffe von einem Gewicht von 0. Eine Suchmaschine könnte die Bestimmung der Ähnlichkeit zwischen Anfrage und Dokument nutzen, um eine gerankte Ergebnisliste zu generieren. Wie sähe diese Liste aus? Erstellen Sie bitte eine gerankte Ausgabeliste der Dokumente 1 bis 4 für diese Suchanfrage.