- Hintergrund: Automatische Erkennung von Ähnlichkeiten zwischen Dokumenten
- Einfaches Umsetzungsbeispiel: Dokument-Deskriptor-Matrix
- Komplexeres Modell: Das Vektorraummodell
1. Hintergrund: Automatische Erkennung von Ähnlichkeiten zwischen Dokumenten
Das Erkennen von ähnlichen Mustern in Dokumenten ist eine der Hauptaufgaben der automatischen Verarbeitung natürlicher Sprache. Diese Muster können genutzt werden, um Dokumente automatisch miteinander zu vergleichen, zu bündeln oder zu klassifizeren. Dazu muss man sich zunächst Gedanken über einige grundlegende Fragen machen.
- Welche Eigenschaften eines Dokumentes eignen sich für die Ermittlung von Ähnlichkeiten?
- Welche Modelle von natürlicher Sprache kann man nutzen für die automatische Verarbeitung von Sprache?
- Welche Aufgaben aus der Praxis lassen sich mit diesen Methoden sinnvoll lösen?
Viele Ansätze des Ähnlichkeitsvergleichs basieren auf dem Vorkommen von Wörtern oder Phrasen in Dokumenten. Häufig wird auch
noch ausgewertet, in welchem Teil eines Dokumentes (Titel, der URL, einem Abschnitte oder in einem Hyperlink) ein Wort vorkommt und mit welchen anderen Wörtern
es gemeinsam auftritt. Grundsätzlich kann man jede Art von Metadaten (z. B. auch Social Media Daten wie User Ratings) zum Merkmalsableich verwenden. Das gleichzeitige Vorkommen einzelner
Merkmale in mehreren Dokumenten nennt man Kookkurenz.
Dieser Art des Ähnlichkeitsvergleichs liegt dann das naheliegende Modell zugrunde, dass Texte, in denen dieselben oder ähnliche Wörter
vorkommen, eine ähnliche Bedeutung haben. Im Alltag trifft diese Annahme häufig zu.
Das muss aber nicht so sein. Schauen Sie sich
diese Briefanfänge an, in denen mit denselben Wörtern eine komplett andere Aussage erreicht wird.
| Brief 1 | Brief 2 |
| Dear John, I want a man who knows what love is all about. Your are generous, kind, thoughtful. People who are not like you admit to being useless and inferior. You have ruined me for other men ... Gloria | Dear John, I want a man who knows what love is. All about your are generous, kind thoughtful people who are not like you. Admit to being useless and inferior. You have ruined me. ... Gloria |
2. Umsetzungsbeispiel: Die Dokument-Deskriptor-Matrix
Die Ähnlichkeit zwischen zwei Objekten wird als Funktion der Anzahl der Eigenschaften berechnet, die beiden Objekten gemeinsam sind. Eine Gemeinsamkeit von Dokumenten kann die Zuordnung von Schlagworten (tags) zu diesen Dokumenten sein.
Die Zuordnung von Schlagworten zu einem Dokument lässt sich gut in Form einer Tabelle vorstellen. In ihrer einfachsten, binären, Form kann man in einer solchen Tabelle festhalten, ob einem Dokument ein Schlagwort zugeordnet wird oder nicht. Dok 1 lautet im Volltext
"Protest gegen Sparmaßnahmen und Sternmarsch zum Rathaus." Nur die fett gedruckten
Wörter wurden in die Tabelle übernommen.
| Schlagwort | Dok 1 | Dok 2 | Dok 3 | Dok 4 |
| Student | 0 | 1 | 0 | 1 |
| Protest | 1 | 1 | 1 | 1 |
| Sparmaßnahme | 1 | 1 | 0 | 1 |
| Sternmarsch | 1 | 0 | 1 | 1 |
| Senat | 1 | 0 | 1 | 1 |
Das Dokument 1 wird durch die in der Spalte Dok 1 angefügten Schlagworte repräsentiert. Diese Spalte kann man auch in Form eines Vektors mathematisch darstellen. Die Ähnlichkeit zwischen zwei Vektoren, in unserem Fall also Repräsentanten für zwei Dokumente, kann man ermitteln, wenn man die beiden Vektoren miteinander multipliziert. Für die Multiplikation wird jeder Wert innerhalb eines Vektors mit dem entsprechenden Wert des anderen Vektors multipliziert. Die Werte werden also paarweise multipliziert. Es können nur Vektoren mit derselben Anzahl Dimensionen miteinander multipliziert werden. Als Ergebnis entsteht ein neuer Vektor. Die einzelnen Werte innerhalb des Vektors können anschließend zu einem Ergebnis addiert werden. Wir können jetzt ausrechnen, ob Dokument 4 oder Dokument 2 eine größere Ähnlichkeit zu Dokument 1 aufweist, indem wir die Dokumente paarweise miteinander multiplizieren.
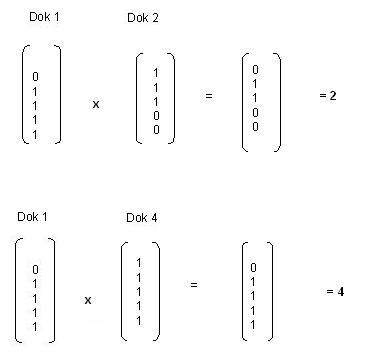 |
Das Skalarprodukt von Dok 1 und Dok 4 errechnet man also, indem man die einzelnen Werte des Vektors miteinander multipliziert und addiert:
0*1 + 1*1 + 1*1 + 1*1 +1*1 = 4
Aus dem Ergebnis können wir schließen, dass Dok 1 und Dok 4 (Skalarprodukt = 4) sich ähnlicher sind als Dok 1 und Dok 2 (Skalarprodukt = 2).
Die gängige mathematische Formeldarstellung für dieses sogenannte Skalarprodukt sieht so aus:
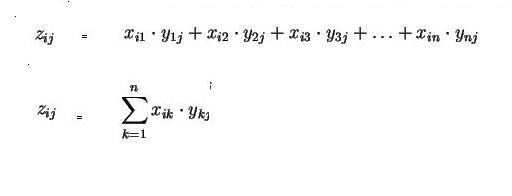 |
Dieses Wissen reicht bereits aus, um mit Vektoren rechnen zu können und auf diese Weise Änhlichkeiten zwischen Dokumenten zu errechnen.
3. Komplexeres Modell: Vektorraummodell
Diese Ähnlichkeitsfunktion wird in der Fachliteratur als Vektorraummodell bezeichnet.
Mit Vektoren wird vor allem in der Physik gearbeitet. Es gibt physikalische Größen, wie z. B. die Temperatur, die sich durch eine Zahl ausdrücken lassen. Andere Größen bestehen aus mehreren Werten: So hat die auf einen Körper ausgeübte Kraft eine Richtung und eine Stärke. Solche Größen nennt man Vektoren. Ein Vektor kann aus beliebig vielen Merkmalen bestehen.
Auch die in den Spalten der Dokument-Deskriptor-Matrix festgehaltenen Dokumente lassen sich mathematisch als Vektoren darstellen. Die Schlagworte bilden die Dimensionen des Vektorraums. Wenn für ein Dokument 5 Schlagworte bestimmt werden, besitzt der Vektor des Dokuments 5 Dimensionen (n=5). 5 Dimensionen sind für uns graphisch nicht mehr umsetzbar. In den aufgeführten Links können Sie sich einige Beispiele für Visulisierungen des Modells ansehen. Aus Gründen der Darstellbarkeit müssen sich die Visualisierungen auf drei Dimensionen beschränken.
Links zu Visalisierungen des Vektorraummodells
Mehr zum Vektorraummodell in Dirk Lewandowski: Web Information Retrieval, Kapitel "Modelle des Information Retrieval" (aufgerufen: 7. Dezember 2014).
Beispiel aus einem Software-Tutorial, das zeigt, wie aus Zeichenketten (Wörtern) Vektorräume werden. Gensim: Corpora and Vector Space
Reginald Ferber: Information Retrieval, Kapitel 1.3.6. http://information-retrieval.de/irb/ir.part_1.chapter_3.section_6.topic_1.html
Einfache Erklärung zur Berechnung der Winkel zwischen Vektoren http://www.youtube.com/watch?v=pRsIUubHtCM
Auch zum Vektorraummodell gibt es ein interessantes Online-Video von der Universität Stanford:The Vector Space Model (VSM) von Dan Jurafsky auf Englisch
Stand: 29. Mai 2018