Automatische Klassifikation: Zuordnung zu einer vorgegebenen Klassifikation
Unter Klassifikation im eigentlichen Sinne versteht man eine Zuordnung von Dokumenten zu bereits vorher festgelegte Klassen. Zum Einstieg können Sie sich eine kurze Demo der Software ACT-DL (Automatic Classification Toolbox for Digital Libraries) ansehen. Klicken Sie bitte auf das Bild.
- Statische Verfahren der automatischen Klassifikation
- Lernende Verfahren der automatischen Klassifikation
- Beispiele aus der Praxis
- Literatur
Man kann grob statische Verfahren und dynamische, lernende Verfahren unterscheiden. Im Folgenden werden die einzelnen Arbeitsschritte beider Verfahren grob schematisch dargestellt.
Statische Verfahren der automatischen Klassifikation
- Voraussetzung für die automatische Klassifikation ist das Vorliegen einer Klassifikation mit bestimmten Merkmalen. Im einfachsten Falle können der Klasse zugeordnete Stich- oder Schlagworte solche Merkmale sein. Solche Schlüsselwörter können z. B. auch aus den einer Klasse zugeordneten Unterbegriffen gewonnen werden. Häufig wird aber auch eine Analyse von Dokumenten, die einer Klasse zugeordnet sind, vorgenommen und statistisch ermittelt, welche Schlagwörter für Dokumente dieser Klasse vergeben werden. Die vergebenen Schlagwörter bilden dann die Merkmale dieser Klasse.
- In einfachen Anwendungen der automatischen Klassifikation werden die vorher intellektuell bestimmten Merkmale einer Klassifikation, z. B. die ihr zugeordneten Deskriptoren, mit den zu klassifizierenden Dokumenten verglichen. Genauer gesagt, wird das Vorkommen bestimmter Terme im Dokument mit dem Vorkommen dieser Terme in der Beschreibung der Klasse verglichen. Dies kann über die Bildung von Skalarprodukten zwischen den Dokumentvektoren und den Vektoren der Klassen geschehen.
Lernende Verfahren der automatischen Klassifikation
- Die Klassenbeschreibungen werden im Rahmen eines automatischen Trainingprozesses 'erlernt'. Ein intellektuell klassifizierter Bestand von Trainingsdokumenten wird daraufhin analysiert, nach welchem Muster die Dokumente den Klassen zugeordnet werden. Hierzu werden Merkmale gesammelt, die Dokumente haben, die einer Klasse zugeordnet sind. Häufig ausgewertete Eigenschaften sind Vorkommen und Gewicht bestimmter Indextermini in den einer Klasse zugeordneten Dokumenten. Hierzu werden z. B.
- die häufigsten gemeinsamen Terme einer Klasse ermittelt
- die Häufigkeiten dieser Terme in anderen Klassen ermittelt
- Terme werden einer Klasse zugewiesen, wenn sie in dieser Klasse häufig, in anderen Klassen hingegen selten vorkommen
- Nachdem anhand des Trainingsbestandes festgelegt wurde, welche Merkmale (z. B. Vorkommen bestimmter Wörter) repräsentativ für eine Klasse sind, können neue Dokumente den Klassen zugeordnet wurden. Dazu müssen die Bedingungen festgelegt werden, die zur Zuweisung eines Dokumentes zu einer Klasse führen. Solche Bedingungen können sein:
- Anzahl von Termen, die einer Klasse zugeordnet sind, die ein Dokument mindestens enthalten muss
- Festlegung von Schwellenwerten für Gewichte
- Es gibt unterschiedliche Verfahren, wie das Klassifikationsmodell erlernt werden kann.
- Probabilistische Verfahren. Für den Trainingsbestand wird für die einzelnen Dokumente die Wahrscheinlichkeit berechnet, mit der Dokumente mit welchen Eigenschaften welcher Klasse zugeordnet werden. Diese Wahrscheinlichkeiten 'lernt' das Verfahren und ordnet auf dieser Grundlage neue Dokument in die wahrscheinlichste Klasse ein.
Grundlage vieler Verfahren ist der "Naive Bayes Algorithmus" (auch Relation Z genannt). Der Algorithmus wird als 'naiv' bezeichnet, da er davon ausgeht, dass die berücksichtigten Eigenschaften voneinander unabhängig sind.
Formel: P(A/B)=P(B/A)*(P(A)/P(B))
P = Wahrscheinlichkeit, A = Ereignis A, B = Bedingung.
Formel in Worten: Die Wahrscheinlichkeit, dass ein Ergeignis A unter der Bedingung B eintritt, ergibt sich aus dem Produkt der Wahrscheinlichkeit von B unter Bedingung A und der Gesamtwahrscheinlichkeit von A geteilt durch Gesamtwahrscheinlichkeit von B.
- Probabilistische Verfahren. Für den Trainingsbestand wird für die einzelnen Dokumente die Wahrscheinlichkeit berechnet, mit der Dokumente mit welchen Eigenschaften welcher Klasse zugeordnet werden. Diese Wahrscheinlichkeiten 'lernt' das Verfahren und ordnet auf dieser Grundlage neue Dokument in die wahrscheinlichste Klasse ein.
- Support Vector Machine (SVW). Dieser Ansatz beruht auf dem Vektorraummodell. Das System wertet die Merkmalsvektoren der Dokumente einer Klasse aus. Mit der Vector Machine soll eine möglichst eindeutige Zuordnung der Dokumenten in Klassen erreicht werden. Deswegen werden Dokumente, die in mehrere Klassen fallen könnten nicht berücksichtigt. Ausgangsbasis Menge von in eine Klassifikation eingeordneten Trainingsdokumenten. Jedes Dokument wird durch einen Vektor im Vektorraum repräsentiert. Die Support Vector Machine zieht in diese Raum eine weitere Ebene (Hyperebene) ein, die Trainingsobjekte in zwei Klassen teilt. Der Abstand derjenigen Vektoren, die der Hyperebene am nächsten liegen, wird dabei maximiert. In der Graphik unten ist die Hyperebene A besser geeignet, die Dokumentvektoren zu trennen als B. Beim Einsetzen der Hyperebene müssen nicht alle Trainingsvektoren berücksichtigt werden. Vektoren, die weiter von der Hyperebene entfernt liegen, beeinflussen Lage und Position der Trennebene nicht.
Beispiel Spamfilter: Für einzelnen Merkmale (Vorkommen von Wörtern in den Emails eines Mailaccounts) wird, die Wahrscheinlichkeit ermittelt, ob es sich um Spam handelt. Wenn in 100 Spammails 70 Mails von einem Server mit der Endung .com stammen, ist die Wahrscheinlichkeit 70/100, dass eine Mail im Spamordner von einer Domain .com stammt. Diese Wahrscheinlichkeit wird in Relation zum Vorkommen von Mails, die von einer Domain .com stammen in allen Emails gesetzt.
Die rein auf der Ermittlung von Ähnlichkeiten durch die Bildung des Skalarproduktes beruhende Zuteilung von Dokumenten zu Klassen kann auf diese Weise also verfeinert werden. Das Klassifikationsverfahren "lernt" hinzu. Zu Beginn 'weiss' es nur, dass ein Term x ein Attribut einer Klasse ist, nach einigen Klassifikationsdurchläufen hat es gelernt, mit wie hoher Wahrscheinlichkeit, ein Dokument, das diesen Term enthält, auch tatsächlich der entsprechenden Klasse zuzuordnen ist.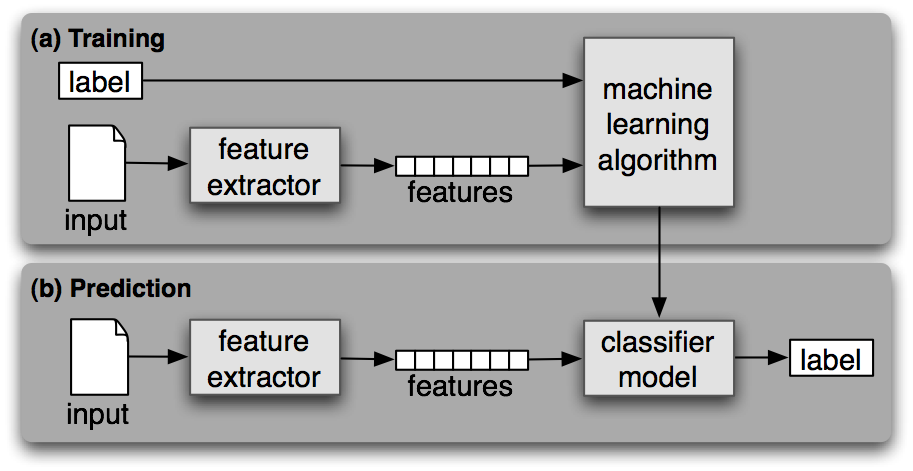
Quelle: Bird u. a.: 6. Learning to Classify Text

Quelle: CC BY Ennepetaler86 (https://commons.wikimedia.org/wiki/File:Svm_intro.svg)
Erfahrung aus der Praxis:
"... [es] sind fünfzig bis hundert oder mehr manuell zugeordnete Beispieldokumente pro Kategorie notwendig, um sicherzustellen, dass die Ergebniskategorien von hoher Qualität sind. Der Nachteil der Naive-Bayes-Kategorisierung ist also, dass sie viele Beispiele braucht. Man kann mit dem Kategorisieren nicht anfangen, bevor man nicht hunderte oder gar tausende von Beispielen erstellt hat, um das System zu trainieren." (Quelle: Peter Gottschalk: Intelligente Suchmaschinentechnologie im Einsatz - Die Schweizer Mediendatenbank SMD. In : Informationskompetenz 2.0. - 24. Oberhofer Kolloquium zur Praxis der Informationsvermittlung - im Gedenken an Joseph Weizenbaum. - Barleben/Magdeburg 10. bis 12. April 2008. Tagungsband Hrsg. von Marlies Ockenfeld. - Frankfurt a.M.: DGI, 2008, S. 161)
1. Das vom Joint Research Centre der Europäischen Kommission publizierte Angebot NewsBrief klassifiziert automatisch Presseartikel aus den weltweit wichtigsten Tageszeitungen (ca. 1000 Klassen und über 30.000 Schlagwortmuster).
3. Automatisches Klassifizieren ist in der Pressedokumentation (DocCat bei Gruner + Jahr, LEXIS-NEXIS) und in der Patentdokumentation im Routineeinsatz - allerdings nur im Sinn einer vorschlagenden Vorklassifizierung, die der intellektuellen Kontrolle bedarf.
4. Beispiel für eine (intellektuell erstellte) Regel, die für LEXIS-NEXIS Dokumente der Klasse 'Joint Venture' zuordnet; die Regel ist eine Tabelle am Ende des Dokuments.
5. BASE der Universitätsbibliothek Bielefeld bietet ein Browsing durch eine Sammlung von 28 Millionen wissenschaftlicher Dokumente an. Ca. 400.000 davon stehen bisher in der Browsinghierarchie zur Verfügung. Die Dokumente wurden den ersten 2-3 Ebenen der DDC vollautomatisch zugeordnet. Dies geschah auf der Basis einer intellektuell klassifizierten Trainingsmenge: BASE Lab: Browsing. Probieren Sie den Bielefeld DDC Classifier selbst aus!
Bird, Steven; Klein, Ewan; Loper, Edward: 6. Learning to Classify Text. In: Dieselb.: Natural Language Processing with Python. : Analyzing Text with the Natural Language Toolkit. Online: http://www.nltk.org/book/ Abruf: 2017-12-06
Croft, W. Bruce; Metzler, Donald; Strohman, Trevor: Chapter 9. Classification and Clustering. In: Dieselb.: Search Engines : Information Retrieval in Practice. Boston : Addison-Wesley, 2010. S. 343-399.
Hoffmann, Robert: Entwicklung einer benutzerunterstützten automatisierten Klassifkation von Web-Dokumenten. - Diplomarbeit, Graz 2002, insbesondere Kap. 4
http://www.iicm.edu/cguetl/education/thesis/rhoff/dagegliedert/Hoffmann_DA_4.htm
Kasprzik, Anna: Automatisierte und semiautomatisierte Klassifizierung : Eine Analyse aktueller Projekte. In: Perspektive Bibliothek 3.1(2014). S. 85-110. https://journals.ub.uni-heidelberg.de/index.php/bibliothek/article/download/14022/7905
Oberhauser, Otto: Automatisches Klassifizieren: Entwicklungsstand - Methodik - Anwendungsbereich. Frankfurt a. M. : Lang,2005
Steinberger, Ralf; Bruno Pouliquen & Erik van der Goot: An introduction to the Europe Media Monitor family of applications. In: Gey, Frederic; Kando, Noriko; Karlgren, Jussi: Proceedings of the SIGIR 2009 Workshop July 23, 2009 Boston, Massachusetts USA : Information Access in a Multilingual World. Boston 2009, S. 1-9. Online: https://www.researchgate.net/profile/Erik_Van_der_Goot/publications. Zugriff: 2016-01-05
Wätjen, Hans-Joachim: GERHARD - Automatisches Sammeln, Klassifizieren und Indexieren von wissenschaftlich relevanten Informations-Ressourcen im deutschen World Wide Web. In: B.I.T. Online (1998) 4, S. 279-290, insbesondere Abschnitte 2., 4., 5.2. und 5.3.-5.3.3.
Bericht über das Projekt GERHARD für die DFG 1998 (deutsch) Abschnitt 3.4
Rapke, Kristin: Automatische Indexierung von Volltexten für die Gruner+Jahr Pressedatenbank. In: Information Research & Content Management. 23.Online-Tagung und 53 Jahrestagung der DGI, 8.-10. Mai 2001. Hrsg. v. Ralph Schmidt. - Frankfurt/Main : DGI, 2001
Universitätsbibliothek Bielefeld: Automatische Klassifikation nach DDC (Kurzerklärung des DDC Klassifikators). http://www.ub.uni-bielefeld.de/wiki/AlexAutoklass

{kind=link}