Berechnung von Präzision und Recall im Information Retrieval
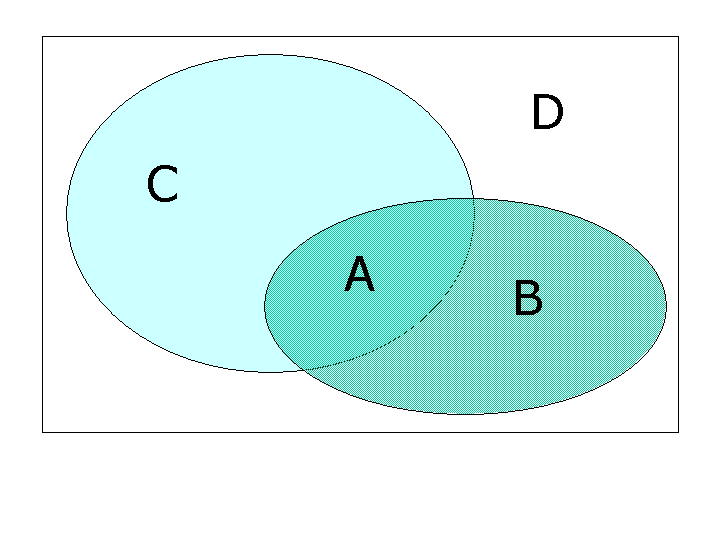
A = Anzahl der relevanten Datensätze, die bei einer Recherche gefunden wurden
B = Anzahl der nicht relevanten Datensätze, die bei einer Recherche gefunden wurden
C = Anzahl der relevanten Datensätze, die bei einer recherche nicht gefunden wurden
D = Anzahl der nicht relevanten Datensätze, die bei einer Recherche nicht gefunden wurden
Anteil der gefundenen Datensätze in Relation zu allen Datensätzen, d.h. wieviel % von den Datensätzen, die hätten gefunden werden müssen, wurden überhaupt gefunden?
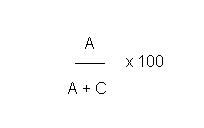
Anteil der gefundenen relevanten Datensätze in Relation zu allen Datensätzen, die gefunden wurden, d.h. wieviel von den gefundenen Datensätzen sind überhaupt nützlich?
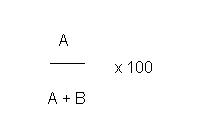
Recall und Präzision werden zu einem Einheitsmaß kombiniert. Dabei kann entweder dem Kriterium Recall oder dem Kriterium Präzision durch den Gewichtungsfaktor b ein höheres Gewicht eingeräumt werden. Setzt man z.B. b = 2, legt man ein doppelt so großes Gewicht auf den Recall. Setzt man b = 0.5, legt man ein doppeltes Gewicht auf die Präzision im Information Retrieval. Für b = 1 sind Recall und Präzision gleichwertig.
e liegt zwischen 0 und 1. e = 0 ist der angestrebte Idealwert, nach dem alle relevanten und nur die relevanten Datensätze wiedergewonnen wurden. e = 1 bedeutet: Kein einziger relevanter Datensatz wurde gefunden.
| e = 1 - | (b2 + 1) x p x r |
| (b2 x p + r) |
b = Gewichtungsfaktor
r = Recall (nicht in %)
p = Präzision (nicht in %)
Vereinfacht nach: Grummann, S. 301